Share

The AI & Tech Society by Danar
Musk vs. Altman: The OpenAI Legal Battle Explained
Season 4, Ep. 24
•
For Tech Leaders
- Corporate structure creates 5-10 year litigation exposure
- Nonprofit pivots require AG negotiation, not just board approval
- Mission-aligned structures (PBC) gain credibility advantage
- Document founder discussions formally
- Co-founder departure terms matter more than ever
- Governance risk is now diligence requirement
- Demand mission-protection documentation
- Monitor AG agreements and state oversight
- Understand partner-investor risk compounding
More episodes
View all episodes

32. The State of AI Engineering: What a Thousand Companies' Telemetry Reveals
19:26||Season 4, Ep. 32Five Moves for LeadersAdopt a model gateway — centralize routing, failover, governanceBuild deprecation discipline — retire models deliberatelyInstrument agents deeply — especially with frameworksAudit prompt caching — fix layout (stable first, dynamic later)Implement budgets & backpressure — cap loops, build queuesSeven Key TakeawaysMulti-model is the norm (70%+ use 3+ models); use a gatewayLLM tech debt compounds; retire old models deliberatelyFramework adoption doubled; observability burden doubled too69% of tokens are system prompts; only 28% use cachingContext windows exploded but quality beats volumeRate limits are the #1 failure modeAgents are still mostly monoliths; distributed shift is comingKey Quotes"The gap between a good demo and a dependable system is closed by effective evaluation and operational discipline." — Datadog"The next wave of agent failures won't be about what agents can't do. It'll be about what teams can't observe." — Guillermo Rauch, CEO, Vercel"Context quality, not volume, is the new limiting factor for LLM agents."
31. SpaceX Buys Cursor: Rockets, AI, and the $60 Billion Bet
16:07||Season 4, Ep. 31The xAI Merger BackgroundFebruary 2026: SpaceX announces xAI acquisitionFinalized May 6, 2026xAI valued at ~$250 billionCreated vertically integrated "innovation engine"Brings Grok, Colossus supercluster, X platform under SpaceX
30. AI Model Cost War: Claude Fable 5 vs Chinese Open Source Models
19:44||Season 4, Ep. 30Fable 5 vs Chatgpt 5.5 vs Opus 4.8 vs Kimi 2.6 vs Qwen 3.7UPDATED ** CLAUDE FABLE JUST GOT SUSPENDED 2026-06-12 BY ANTHROPIC AND THE US GOVERNMENT.The Token Efficiency WrinkleFable 5 uses fewer tool calls than Opus-tier models25-30% faster on Anthropic's spreadsheet suiteFewer turns partially offset the 2x per-token priceMeasure cost per outcome, not cost per tokenFable 5 Safeguard ArchitectureNovel design: Routes risky prompts to less capable model rather than refusingClassifier domains:CybersecurityBiology and chemistryModel distillationFallback model: Claude Opus 4.8 Trigger rate: <5% (Anthropic) / 8-9% (Artificial Analysis) Security testing: 1,000+ hours bug bounty, no universal jailbreak foundKey Quotes"It's like hiring a brain surgeon to put on a band-aid.""There is no best model. There's only the best model for this task, at this input/output ratio, with this latency tolerance.""Everyone will have access to the smartest model. The decisive competency is knowing when not to use it.""The first phase of enterprise AI was about access. The next phase is about allocation."
29. Claude Opus 4.8: Benchmark Results and Review
17:37||Season 4, Ep. 29Claude Opus 4.8 Review and Benchmark resultsKey insight: 10.6-point gap on SWE-bench Pro is the largest between Opus 4.8 and GPT-5.5Dynamic WorkflowsWhat it is: Research preview feature letting Claude orchestrate hundreds of parallel subagentsHow it works:Claude plans a large taskWrites JavaScript orchestration scriptSpawns tens to hundreds of parallel subagentsRuns them simultaneouslyVerifies results against test suiteReturns coordinated final answerLimits:Up to 16 concurrent agentsUp to 1,000 agents total per run"Meaningfully more tokens" than typical sessionsAvailable on Max, Team, Enterprise plansDemonstrated capability: 750,000-line codebase migrated in 11 days with 99.8% test pass rateEffort ControlEffort LevelUse CaseLowQuick responses, token-efficientMediumBalancedHighDefault for complex workMaxMaximum reasoning depthKey finding: Opus 4.8 at minimum effort matches Opus 4.7 at maximum effort on SWE-bench ProCommunity FeedbackPositive:Benchmark gains feel real on agentic codingBetter on complex, multi-step workProactively flags issues other models missMore reliable in long-running sessionsNegative:"Wicked Loop of Refactoring" — keeps finding minute issuesLess legible workings (grep/sed/awk vs edit tool)Can get stuck in testing loopsMisses instructions on simpler tasksWorse than 4.7 on some UI generation prompts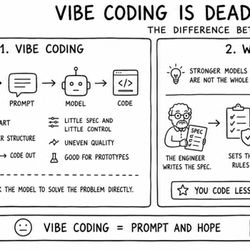
28. Vibe Coding Is Dead: The Rise of Agentic Engineering
16:05||Season 4, Ep. 28The Three-Panel FrameworkPanel 1: Vibe CodingYou → Prompt → Model → CodeFast to startFeeling over structureGood for prototypes"You ask the model to solve the problem directly"Panel 2: What ChangedStronger models are not the whole answerThe new bottleneck is context, rules, and reviewEngineer writes spec → Sets rules → Lets agents work → Reviews output"You code less. You steer the system more."Panel 3: Agentic EngineeringAgents build. The human orchestrates.Bring together: spec, goal, constraints, history, data, rules, tools, tests"More scalable. More repeatable. Better results."Key Quotes"Many people have tried to come up with a better name for this to differentiate it from vibe coding. Personally, my current favorite is 'agentic engineering.'" — Andrej Karpathy"The goal is to claim the leverage from the use of agents but without any compromise on the quality of the software." — Andrej Karpathy"I think by the end of the year, everyone is going to be a product manager, and everyone codes. The title software engineer is going to start to go away." — Boris Cherny"You can outsource your thinking but you can't outsource your understanding." — Tweet Karpathy thinks about every other day
27. Claude Code at the Organization Layer: What Actually Changes
19:20||Season 4, Ep. 27What Actually Changes When Claude Code Reaches the Whole Engineering OrganizationMetrics That Actually MatterStop measuring:Lines of code per developerToken consumptionIndividual productivityStart measuring:Cycle time (Claude-assisted vs non-assisted PRs)Time to first PR for new hiresPR throughput with quality counterweight (defect rate, rollback frequency)Incident resolution timeMaintenance burden trajectoryNon-Engineers Building SoftwareExamples from one company:Support team: Tool surfacing relevant past tickets and customer historyFinance team: Expense categorization assistantHR team: Onboarding checklist app pulling from live systemsWhat engineering built:Architecture patterns for internal appsPlugin marketplace with pre-approved skills/MCP connectionsManaged permissions (read from X, write to Y, not Z)Audit logs for AI-generated changesThe shift: Engineering didn't build the apps. Engineering built the conditions under which apps could be built safely.
26. The SaaS Model Is Breaking, and AI Agents Are the Reason
10:08||Season 4, Ep. 26So, quick context before we dive in. A couple of weeks ago I published a piece on my blog about how AI agents are quietly breaking the SaaS pricing model. And honestly? I didn't expect what happened next. The post just… took off. My inbox has been wild. CFOs, founders, a few VCs, even a couple of procurement leads who I'm pretty sure have never emailed anyone voluntarily in their lives. All asking the same kinds of questions.
25. Gemma 4: Google's Open-Source LLM Competing with Chinese Models
18:20||Season 4, Ep. 25Why Apache 2.0 MattersPrevious Gemma licensing:Custom "Gemma Terms of Use"Usage-policy provisionsConstraints on commercial deploymentApache 2.0:Fine-tune for commercial use ✓Redistribute fine-tuned variants ✓Embed in commercial products ✓No ongoing license obligations ✓On-Device AI ImplicationsWhat's new:Full conversational AI on phones, offlineNo data leaving deviceNo API costsNo connectivity requirementsUse cases:Healthcare apps (privacy)Education (offline areas)Finance (data sovereignty)Any privacy-sensitive applicationData SovereigntyThe shift:European regulators increasingly uncomfortable with US-hosted APIsGDPR requires either locked regions or self-hostedGemma 4 + Apache 2.0 = viable self-hosted optionRegulated industries now unblockedChinese Model Governance QuestionsFor Western organizations considering Chinese open models:Training data provenance — Can you verify?Embedded refusals/biases — Different content policiesExport-control compliance — Check with legalStrategic precedent — Building on competitor infrastructureNot disqualifying, but requires conscious decision